実行可能ファイル doxygen は、ソースを解析して文書を生成する主要なプログラムです。より詳細な使用方法については、セクション Doxygenの使用方法 を参照してください。
オプションとして、Doxygenで使用する設定ファイルの編集や、グラフィカルな環境でDoxygenを実行するためのグラフィカルなフロントエンドである実行可能ファイル doxywizard を使用できます。macOSでは、DoxygenアプリケーションアイコンをクリックするとDoxywizardが起動します。
次の図は、ツール間の関係と情報の流れを示しています(複雑に見えますが、それは完全にしようとしているからです)。
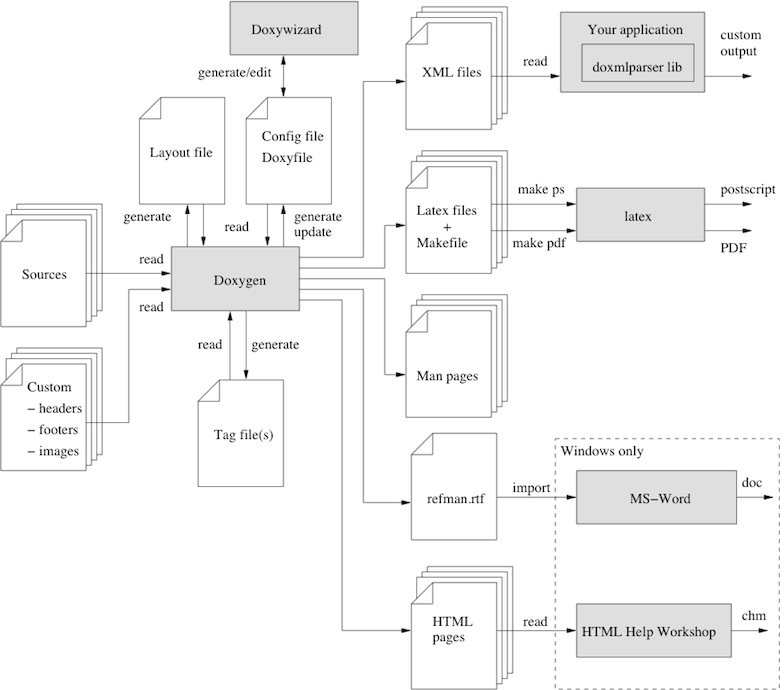
まず、使用するプログラミング/ハードウェア記述言語がDoxygenによって合理的に認識される可能性があることを確認してください。以下のプログラミング言語がデフォルトでサポートされています: C、C++、Lex、C#、Objective-C、IDL、Java、PHP、Python、Fortran、D。Doxygenはハードウェア記述言語VHDLもデフォルトでサポートしています。特定のファイルタイプ拡張子に特定のパーサーを使用するように設定することが可能です。詳細については、設定/拡張マッピング を参照してください。また、プリプロセッサプログラムを使用することで、まったく異なる言語もサポートできます。詳細については、ヘルパーページ を参照してください。
Doxygenは、すべての設定を決定するために設定ファイルを使用します。各プロジェクトは独自の設定ファイルを持つべきです。プロジェクトは単一のソースファイルで構成することもできますが、再帰的にスキャンされるソースツリー全体である場合もあります。
設定ファイルの作成を簡素化するために、Doxygenはテンプレート設定ファイルを自動で作成できます。これを行うには、コマンドラインから doxygen を -g オプションを付けて呼び出します。
doxygen -g <config-file>
ここで、<config-file> は設定ファイルの名前です。ファイル名を省略すると、Doxyfile という名前のファイルが作成されます。<config-file> という名前のファイルが既に存在する場合、Doxygenは設定テンプレートを生成する前にそれを <config-file>.bak にリネームします。ファイル名として - (つまりマイナス記号) を使用すると、Doxygenは標準入力 (stdin) から設定ファイルを読み込もうとします。これはスクリプト作成に役立ちます。
設定ファイルは (シンプルな) Makefileと似た形式を持っています。次のような形式の多数の割り当て (タグ) で構成されます。
TAGNAME = VALUE または
TAGNAME = VALUE1 VALUE2 ...
生成されたテンプレート設定ファイルのほとんどのタグの値は、デフォルト値のままで問題ないでしょう。設定ファイルに関する詳細については、セクション 設定 を参照してください。
テキストエディタで設定ファイルを編集したくない場合は、Doxygen設定ファイルの作成、読み取り、書き込みが可能で、ダイアログを介して設定オプションを設定できるGUIフロントエンドであるDoxywizardを参照してください。
少数のCおよび/またはC++ソースファイルとヘッダーファイルで構成される小規模なプロジェクトの場合、INPUTタグを空のままにすると、Doxygenは現在のディレクトリ内のソースを検索します。
ソースディレクトリまたはツリーで構成される大規模なプロジェクトの場合、ルートディレクトリをINPUTタグに割り当て、1つ以上のファイルパターンをFILE_PATTERNSタグに追加する必要があります (例: *.cpp *.h)。パターンに一致するファイルのみが解析されます (パターンが省略された場合、Doxygenがサポートするファイルタイプに対して一般的なパターンリストが使用されます)。ソースツリーを再帰的に解析するには、RECURSIVEタグをYESに設定する必要があります。解析されるファイルのリストをさらに細かく調整するには、EXCLUDEおよびEXCLUDE_PATTERNSタグを使用できます。例えば、ソースツリーからすべてのtestディレクトリを除外するには、次のように使用できます。
EXCLUDE_PATTERNS = */test/*
Doxygenは、以下のテーブルを使用して、ファイルを解析する方法を決定するためにファイルの拡張子を調べます。
| 拡張子 | 言語 | 拡張子 | 言語 | 拡張子 | 言語 |
|---|---|---|---|---|---|
| .dox | C / C++ | .HH | C / C++ | .py | Python |
| .doc | C / C++ | .hxx | C / C++ | .pyw | Python |
| .c | C / C++ | .hpp | C / C++ | .f | Fortran |
| .cc | C / C++ | .h++ | C / C++ | .for | Fortran |
| .cxx | C / C++ | .mm | C / C++ | .f90 | Fortran |
| .cpp | C / C++ | .txt | C / C++ | .f95 | Fortran |
| .c++ | C / C++ | .idl | IDL | .f03 | Fortran |
| .cppm | C / C++ | .ddl | IDL | .f08 | Fortran |
| .ccm | C / C++ | .odl | IDL | .f18 | Fortran |
| .cxxm | C / C++ | .java | Java | .vhd | VHDL |
| .c++m | C / C++ | .cs | C# | .vhdl | VHDL |
| .ii | C / C++ | .d | D | .ucf | VHDL |
| .ixx | C / C++ | .php | PHP | .qsf | VHDL |
| .ipp | C / C++ | .php4 | PHP | .l | Lex |
| .i++ | C / C++ | .php5 | PHP | .md | Markdown |
| .inl | C / C++ | .inc | PHP | .markdown | Markdown |
| .h | C / C++ | .phtml | PHP | .ice | Slice |
| .H | C / C++ | .m | Objective-C | ||
| .hh | C / C++ | .M | Objective-C |
上記のリストは、デフォルトでFILE_PATTERNSに設定されている項目よりも多くの項目が含まれている可能性があることに注意してください。
解析されない拡張子は、FILE_PATTERNSに追加し、適切なEXTENSION_MAPPINGが設定されていれば設定できます。
既存のプロジェクト (Doxygenが認識するドキュメントがない場合) でDoxygenを使い始めた場合でも、構造がどうなっているか、文書化された結果がどう見えるかを知ることができます。そのためには、設定ファイルのEXTRACT_ALLタグをYESに設定する必要があります。そうすると、Doxygenはソース内のすべてが文書化されているかのように振る舞います。なお、EXTRACT_ALLがYESに設定されている限り、文書化されていないメンバーに関する警告は生成されません。
既存のソフトウェアを分析する場合、(文書化された) エンティティとソースファイル内のその定義を相互参照すると便利です。Doxygenは、SOURCE_BROWSERタグをYESに設定すると、そのような相互参照を生成します。また、INLINE_SOURCESをYESに設定することで、ソースを直接ドキュメントに含めることもできます (これはコードレビューなどに役立ちます)。
文書を生成するには、次のように入力します。
doxygen <config-file>
設定に応じて、Doxygenは出力ディレクトリ内に html、rtf、latex、xml、man、および/または docbook ディレクトリを作成します。名前が示すように、これらのディレクトリにはHTML、RTF、 、XML、Unix Manページ、およびDocBook形式で生成されたドキュメントが含まれます。
、XML、Unix Manページ、およびDocBook形式で生成されたドキュメントが含まれます。
デフォルトの出力ディレクトリは、doxygen が開始されたディレクトリです。出力が書き込まれるルートディレクトリは、OUTPUT_DIRECTORY を使用して変更できます。出力ディレクトリ内のフォーマット固有のディレクトリは、設定ファイルの HTML_OUTPUT、RTF_OUTPUT、LATEX_OUTPUT、XML_OUTPUT、MAN_OUTPUT、および DOCBOOK_OUTPUT タグを使用して選択できます。出力ディレクトリが存在しない場合、doxygen はそれを自動的に作成しようとします (ただし、mkdir -p のように再帰的にパス全体を作成しようとはしません)。
生成されたHTMLドキュメントは、html ディレクトリ内の index.html ファイルをHTMLブラウザで開いて表示できます。最適な結果を得るには、カスケーディングスタイルシート (CSS) をサポートするブラウザを使用する必要があります (私はMozilla Firefox、Google Chrome、Safari、そして時々IE8、IE9、Operaを使用して生成された出力をテストしています)。
HTMLセクションの一部の機能 (例: GENERATE_TREEVIEW や検索エンジン) には、Dynamic HTMLとJavaScriptを有効にしたブラウザが必要です。
生成された ドキュメントは、まず コンパイラでコンパイルする必要があります (私はLinuxとmacOSでは最近のteTeXディストリビューションを、WindowsではMikTexを使用しています)。生成されたドキュメントのコンパイルプロセスを簡素化するために、doxygen は latex ディレクトリに Makefile を書き込みます (Windowsプラットフォームでは make.bat バッチファイルも生成されます)。
Makefile の内容とターゲットは、USE_PDFLATEX の設定によって異なります。無効 (NO に設定) の場合、latex ディレクトリで make と入力すると、refman.dvi という名前の dvi ファイルが生成されます。このファイルは xdvi を使用して表示するか、make ps と入力してPostScriptファイル refman.ps に変換できます (これには dvips が必要です)。
1枚の物理ページに2ページを配置するには、代わりにmake ps_2on1を使用します。結果のPostScriptファイルはPostScriptプリンターに送信できます。PostScriptプリンターがない場合は、Ghostscriptを使用してPostScriptをプリンターが理解できるものに変換してみてください。
Ghostscriptインタープリターがインストールされている場合、PDFへの変換も可能です。単に make pdf (または make pdf_2on1) と入力してください。
PDF出力で最良の結果を得るには、PDF_HYPERLINKS と USE_PDFLATEX のタグを YES に設定する必要があります。この場合、Makefile には refman.pdf を直接ビルドするターゲットのみが含まれます。
DoxygenはRTF出力をrefman.rtfという単一のファイルに結合します。このファイルはMicrosoft Wordへのインポートに最適化されています。特定の情報は、いわゆるフィールドを使用してエンコードされています。実際の値を表示するには、すべてを選択し (編集 - すべて選択)、次にフィールドを切り替える必要があります (右クリックしてドロップダウンメニューからオプションを選択)。
XML出力は、Doxygenによって収集された情報の構造化された「ダンプ」で構成されます。各複合体 (クラス/名前空間/ファイル/...) には独自のXMLファイルがあり、index.xml というインデックスファイルもあります。
combine.xslt というXSLTスクリプトも生成され、すべてのXMLファイルを1つのファイルに結合するために使用できます。
Doxygenは、2つのXMLスキーマファイル index.xsd (インデックスファイル用) と compound.xsd (複合ファイル用) も生成します。このスキーマファイルは、可能な要素、その属性、およびそれらがどのように構造化されているかを記述します。つまり、XMLファイルの文法を記述し、検証やXSLTスクリプトの制御に使用できます。
addon/doxmlparser ディレクトリには、Doxygenによって生成されたXML出力をインクリメンタルに読み込むためのパーサーライブラリが見つかります (addon/doxmlparser/doxmparser/index.py および addon/doxmlparser/doxmlparser/compound.py でライブラリのインターフェースを参照してください)。
生成されたmanページは、man プログラムを使用して表示できます。manディレクトリがmanパスに含まれていることを確認する必要があります (MANPATH 環境変数を参照)。manページ形式の機能にはいくつかの制限があるため、一部の情報 (クラス図、相互参照、数式など) は失われることに注意してください。
DoxygenはDocBook形式でも出力を生成できます。DocBook出力の処理方法は、このマニュアルの範囲外です。
ソースの文書化はステップ3として提示されていますが、新しいプロジェクトではもちろんこれがステップ1であるべきです。ここでは、すでにコードがあり、DoxygenにAPI、場合によっては内部、そして関連する設計ドキュメントを記述した素晴らしいドキュメントを生成してもらいたいと仮定します。
設定ファイルでEXTRACT_ALLオプションがNO (デフォルト) に設定されている場合、Doxygenは文書化されたエンティティのみのドキュメントを生成します。では、これらをどのように文書化するのでしょうか?メンバー、クラス、名前空間の場合、基本的に2つのオプションがあります。
メンバー、クラス、または名前空間の宣言または定義の前に特別なドキュメントブロックを配置します。ファイル、クラス、および名前空間のメンバーの場合、ドキュメントをメンバーの直後に配置することも許可されます。
特別なドキュメントブロックの詳細については、セクション 特別なコメントブロック を参照してください。
特別なドキュメントブロックを別の場所 (別のファイルまたは別の場所) に配置し、かつドキュメントブロック内に構造コマンドを配置します。構造コマンドは、ドキュメントブロックを文書化可能な特定のエンティティ (例: メンバー、クラス、名前空間、またはファイル) にリンクします。
構造コマンドの詳細については、セクション 他の場所での文書化 を参照してください。
最初のオプションの利点は、エンティティの名前を繰り返す必要がないことです。
ファイルは、ファイルより前にドキュメントブロックを配置する方法がないため、2番目のオプションのみを使用して文書化できます。もちろん、ファイルメンバー (関数、変数、typedef、define) には明示的な構造コマンドは必要ありません。それらの前または後ろに特別なドキュメントブロックを配置するだけで問題ありません。
特別なドキュメントブロック内のテキストは、HTMLおよび/または出力ファイルに書き込まれる前に解析されます。
出力のために同等のものに変換されます。サポートされているすべてのHTMLタグの概要については、セクション HTMLコマンド を参照してください。