Doxygenはリリース1.8.3で、外部インデックスツールと検索エンジンを使用してHTMLを検索する機能を提供します。これにはいくつかの利点があります。
誰もが独自のインデクサーと検索エンジンを書き始める必要がないように、Doxygenは各アクションの例ツールを提供しています。データインデックス作成にはdoxyindexer、インデックス検索にはdoxysearch.cgiです。
データフローは以下の図に示されています。
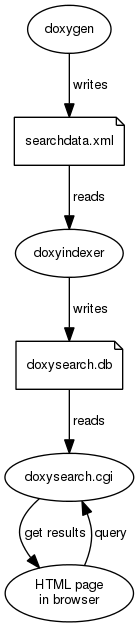
最初のステップは、検索エンジンをWebサーバー経由で利用できるようにすることです。doxysearch.cgiを使用する場合、これはCGIバイナリをWebサーバーから利用できるようにする(つまり、http:で始まるURLを介してブラウザから実行できるようにする)ことを意味します。
Webサーバーの設定方法は本書の範囲外ですが、例えばApacheがインストールされている場合、Doxygenのbinディレクトリからdoxysearch.cgiファイルをApache Webサーバーのcgi-binディレクトリにコピーするだけです。詳細については、Apacheドキュメントを参照してください。
doxysearch.cgiがアクセス可能かどうかをテストするには、Webブラウザを起動し、URLをバイナリに向け、最後に?testを追加します。
http://yoursite.com/path/to/cgi/doxysearch.cgi?test
以下のメッセージが表示されるはずです。
Test failed: cannot find search index doxysearch.db
Internet Explorerを使用している場合、ファイルがダウンロードするように促されることがあり、そのファイルにこのメッセージが含まれます。
doxysearch.dbを作成またはインストールしなかったため、この理由でテストが失敗しても問題ありません。この修正方法については、次のセクションで説明します。
次のセクションに進む前に、上記のURL(?test部分なし)をDoxygenの設定ファイルのSEARCHENGINE_URLタグに追加してください。
SEARCHENGINE_URL = http://yoursite.com/path/to/cgi/doxysearch.cgi
外部検索オプションを使用するには、Doxygenの設定ファイルで以下のオプションが有効になっていることを確認してください。
SEARCHENGINE = YES SERVER_BASED_SEARCH = YES EXTERNAL_SEARCH = YES
これにより、Doxygenは出力ディレクトリ(OUTPUT_DIRECTORYで設定)にsearchdata.xmlというファイルを生成します。ファイル名(および場所)はSEARCHDATA_FILEオプションで変更できます。
次のステップは、効率的な検索のために生の検索データをインデックスに入れることです。これにはdoxyindexerを使用できます。コマンドラインから実行するだけです。
doxyindexer searchdata.xml
これにより、いくつかのファイルを含むdoxysearch.dbというディレクトリが作成されます。デフォルトでは、ディレクトリはdoxyindexerが起動された場所に作成されますが、-oオプションを使用してディレクトリを変更できます。
doxysearch.dbディレクトリをdoxysearch.cgiと同じディレクトリにコピーし、ブラウザを指してブラウザテストを再実行します。
http://yoursite.com/path/to/cgi/doxysearch.cgi?test
これで、以下のメッセージが表示されるはずです。
Test successful.
これで、HTML出力から単語やシンボルを検索できるようになります。
複数のDoxygenプロジェクトがあり、これらのプロジェクトが関連している場合、いずれかのプロジェクトのドキュメント内からすべてのプロジェクトの単語を検索できるようにすることが望ましい場合があります。
これを可能にするには、すべてのプロジェクトの検索データを単一のインデックスに結合するだけです。たとえば、project_Aディレクトリとproject_Bディレクトリにsearchdata.xmlが生成されている2つのプロジェクトAとBの場合、以下を実行します。
doxyindexer project_A/searchdata.xml project_B/searchdata.xml
そして、結果のdoxysearch.dbをdoxysearch.cgiも配置されているディレクトリにコピーします。
searchdata.xmlファイルには絶対パスやリンクが含まれていないため、複数のプロジェクトからの検索結果をどのようにして適切なドキュメントセットにリンクし直すのでしょうか?ここでEXTERNAL_SEARCH_IDとEXTRA_SEARCH_MAPPINGSオプションが重要になります。
異なるプロジェクトを識別できるようにするには、各プロジェクトにEXTERNAL_SEARCH_IDを使用して一意のIDを設定する必要があります。
検索結果を正しいプロジェクトにリンクするには、EXTRA_SEARCH_MAPPINGSタグを使用してプロジェクトごとにマッピングを定義する必要があります。このオプションを使用すると、他のプロジェクトのIDからそれらのプロジェクトのドキュメントの(相対)場所へのマッピングを定義できます。
したがって、プロジェクトAとBの場合、設定ファイルの関連部分は次のようになります。
project_A/Doxyfile ------------------ EXTERNAL_SEARCH_ID = A EXTRA_SEARCH_MAPPINGS = B=../../project_B/html
プロジェクトAとプロジェクトBの場合
project_B/Doxyfile ------------------ EXTERNAL_SEARCH_ID = B EXTRA_SEARCH_MAPPINGS = A=../../project_A/html
これらの設定により、プロジェクトAとBは同じ検索データベースを共有でき、検索結果は正しいドキュメントセットにリンクされます。
ソースコードを変更した場合、再度最新のドキュメントを取得するためにdoxygenを再実行する必要があります。外部検索を使用している場合は、doxyindexerを再実行して検索インデックスも更新する必要があります。このプロセスを簡単にするために、doxygenとdoxyindexerの呼び出しをスクリプトにまとめてもよいでしょう。
これまでのセクションでは、インデックス作成と検索にdoxyindexerとdoxysearch.cgiツールを使用することを前提としていましたが、必要に応じて独自のインデックスおよび検索ツールを作成することもできます。
これには3つのインターフェースが重要です。
次のサブセクションでは、これらのインターフェースについて詳しく説明します。
Doxygenによって生成される検索データは、Solr XMLインデックスメッセージ形式に従います。
インデクサーへの入力はXMLファイルであり、複数の<doc>タグを含む1つの<add>タグで構成され、<doc>タグはさらに複数の<field>タグを含んでいます。
以下は、1つのメソッドの検索データとメタデータを含む1つのdocノードの例です。
<add>
...
<doc>
<field name="type">function</field>
<field name="name">QXmlReader::setDTDHandler</field>
<field name="args">(QXmlDTDHandler *handler)=0</field>
<field name="tag">qtools.tag</field>
<field name="url">de/df6/class_q_xml_reader.html#a0b24b1fe26a4c32a8032d68ee14d5dba</field>
<field name="keywords">setDTDHandler QXmlReader::setDTDHandler QXmlReader</field>
<field name="text">Sets the DTD handler to handler DTDHandler()</field>
</doc>
...
</add>
各フィールドには名前があります。以下のフィールド名がサポートされています。
Doxygenで生成されたHTMLページから検索エンジンが呼び出されると、いくつかのパラメータがクエリ文字列を介して渡されます。
以下のフィールドが渡されます。
検索結果の完全なリストから、範囲[n*p - n*(p+1)-1]が返されるはずです。
以下はクエリの例です。
http://yoursite.com/path/to/cgi/doxysearch.cgi?q=list&n=20&p=1&cb=dummy
これは「list」という単語のクエリ(q=list)を表しており、20件の検索結果(n=20)を要求し、20番目の結果から開始し(p=1)、コールバック「dummy」を使用します(cb=dummy)。
前のサブセクションで示したように検索エンジンを呼び出すと、結果が返されるはずです。応答の形式はJSON with paddingであり、基本的に関数呼び出しにラップされたJavaScript構造体です。関数名はコールバックの名前である必要があります(クエリのcbフィールドで渡されたもの)。
前のサブセクションで示した例のクエリでは、応答の主要な構造は次のようになるはずです。
dummy({
"hits":179,
"first":20,
"count":20,
"page":1,
"pages":9,
"query": "list",
"items":[
...
]})
各フィールドには以下の意味があります。
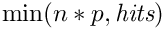 。
。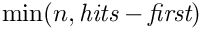
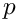
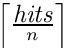 。
。以下は、items配列の要素がどのように見えるべきかの例です。
{"type": "function",
"name": "QDir::entryInfoList(const QString &nameFilter, int filterSpec=DefaultFilter, int sortSpec=DefaultSort) const",
"tag": "qtools.tag",
"url": "d5/d8d/class_q_dir.html#a9439ea6b331957f38dbad981c4d050ef",
"fragments":[
"Returns a <span class=\"hl\">list</span> of QFileInfo objects for all files and directories...",
"... pointer to a QFileInfoList The <span class=\"hl\">list</span> is owned by the QDir object...",
"... to keep the entries of the <span class=\"hl\">list</span> after a subsequent call to this..."
]
},
このようなアイテムのフィールドには、以下の意味があります。
